Zero-shot open-vocabulary segmentation with FreeSeg-Diff. The image is passed to a diffusion model and to an image captioner model to get visual features and text description respectively. The features are used to get class-agnostic masks, which are then associated with the extracted text. The final segmentation map is obtained after a mask refinement step. All models are kept frozen.
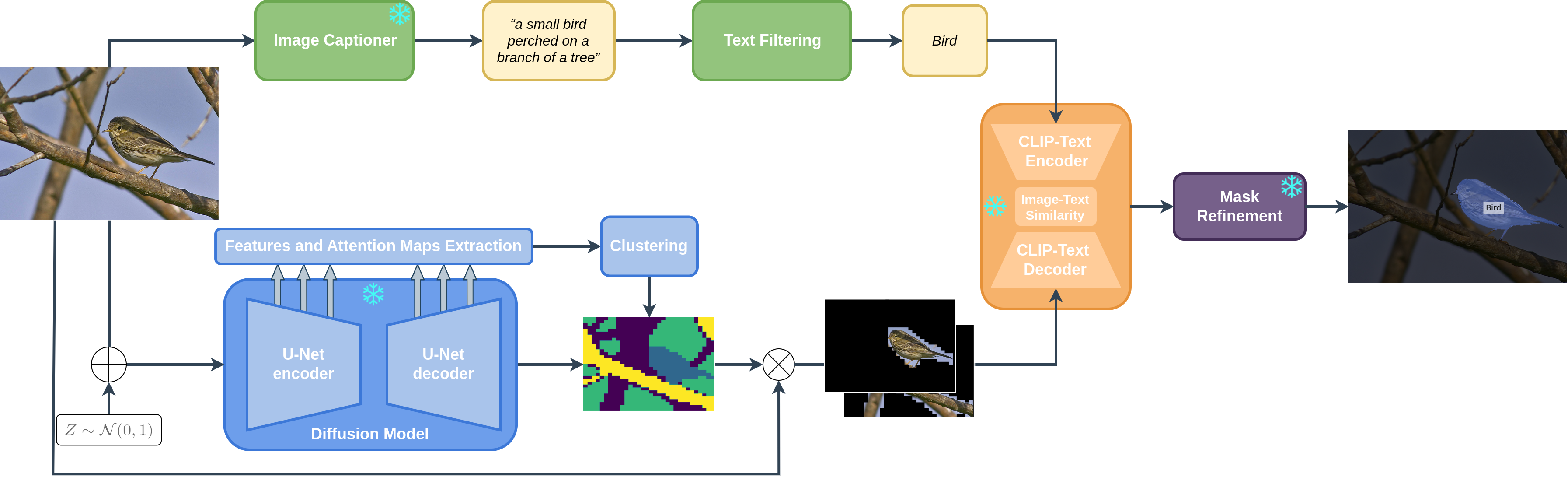
Our detailed pipeline for zero-shot semantic segmentation. We extract features from several blocks of the DM corresponding to a noisy image. These features are clustered to generate class-agnostic masks that are used to produce image crops. These cropped parts are then passed to a CLIP image encoder 𝓥 to associate each mask/cropped image to a given text/class. The textual classes are obtained by generating a caption from BLIP, followed by NLP tools to extract textual entities. These entities are mapped to the most similar mask. Finally, the masks are refined with CRF to obtain the final segmentation map. All models are kept frozen.
























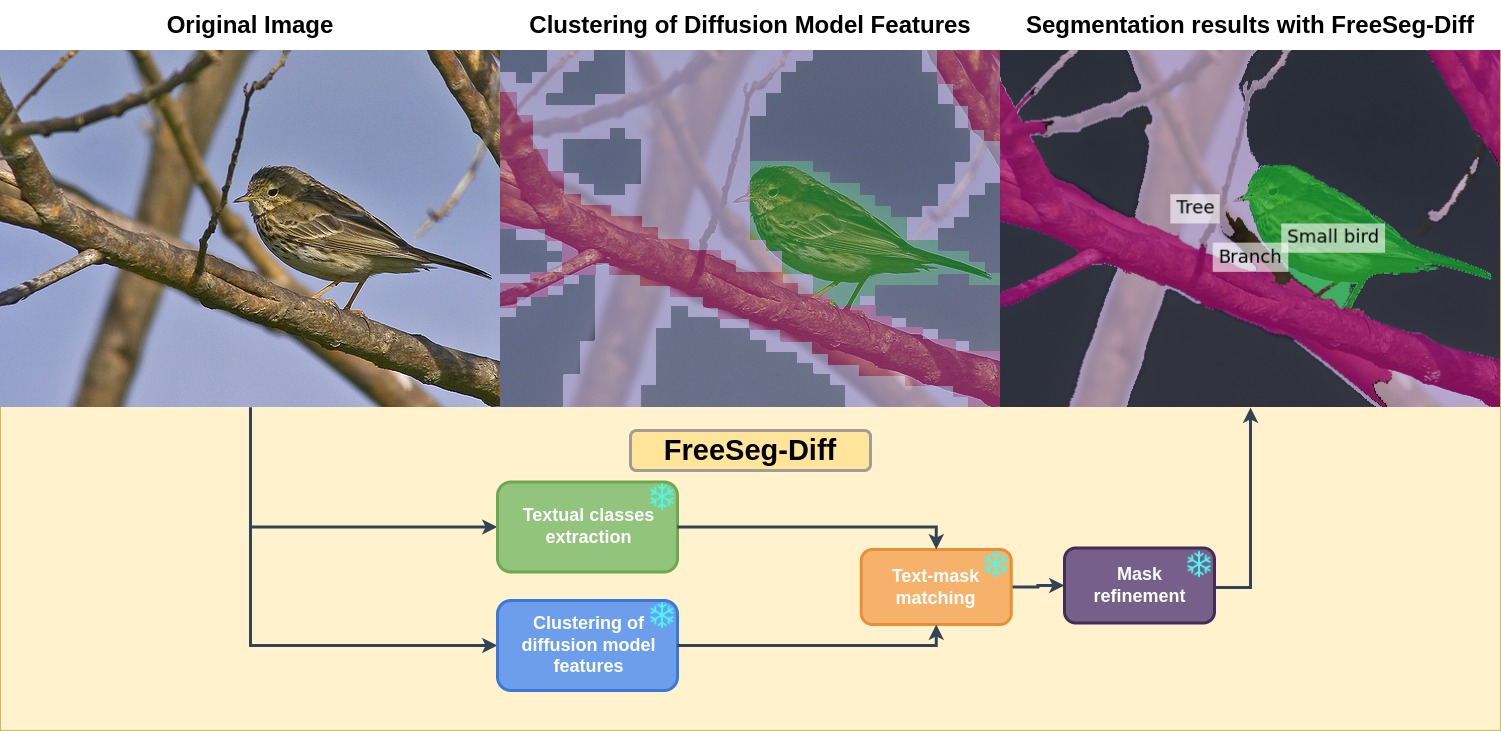
Qualitative results on Pascal VOC dataset. From top to down: original image, raw clustering results of DM features, segmentation results with FreeSeg-Diff. Our pipeline filters out redundant clusters while retaining key objects and refine coarse masks to yield sharp segmentation maps.